Data Collection
Kelly McConville
Stat 100
Week 4 | Fall 2023
Getting Help with R
Novices asking the internet for
Rhelp = 😰Get help from the Stat 100 teaching staff or classmates!
- Will start p-sets in section each week.
- Use the Slack
#q-and-achannel.
- Get help early before 😡 sets in!
- Be prepared for missing commas and quotes, capitalization issues, etc…
- Later in the semester, will learn tricks for effectively getting
Rhelp online.
Load Necessary Packages

dplyr is part of this collection of data science packages.
Now for Data Collection

Who are the data supposed to represent?

Key questions:
- What evidence is there that the data are representative?
- Who is present? Who is absent?
- Who is overrepresented? Who is underrepresented?
Who are the data supposed to represent?
Census: We have data on the whole population!
Who are the data supposed to represent?
Who are the data supposed to represent?
Key questions:
- What evidence is there that the sample is representative of the population?
- Who is present? Who is absent?
- Who is overrepresented? Who is underrepresented?
Sampling Bias
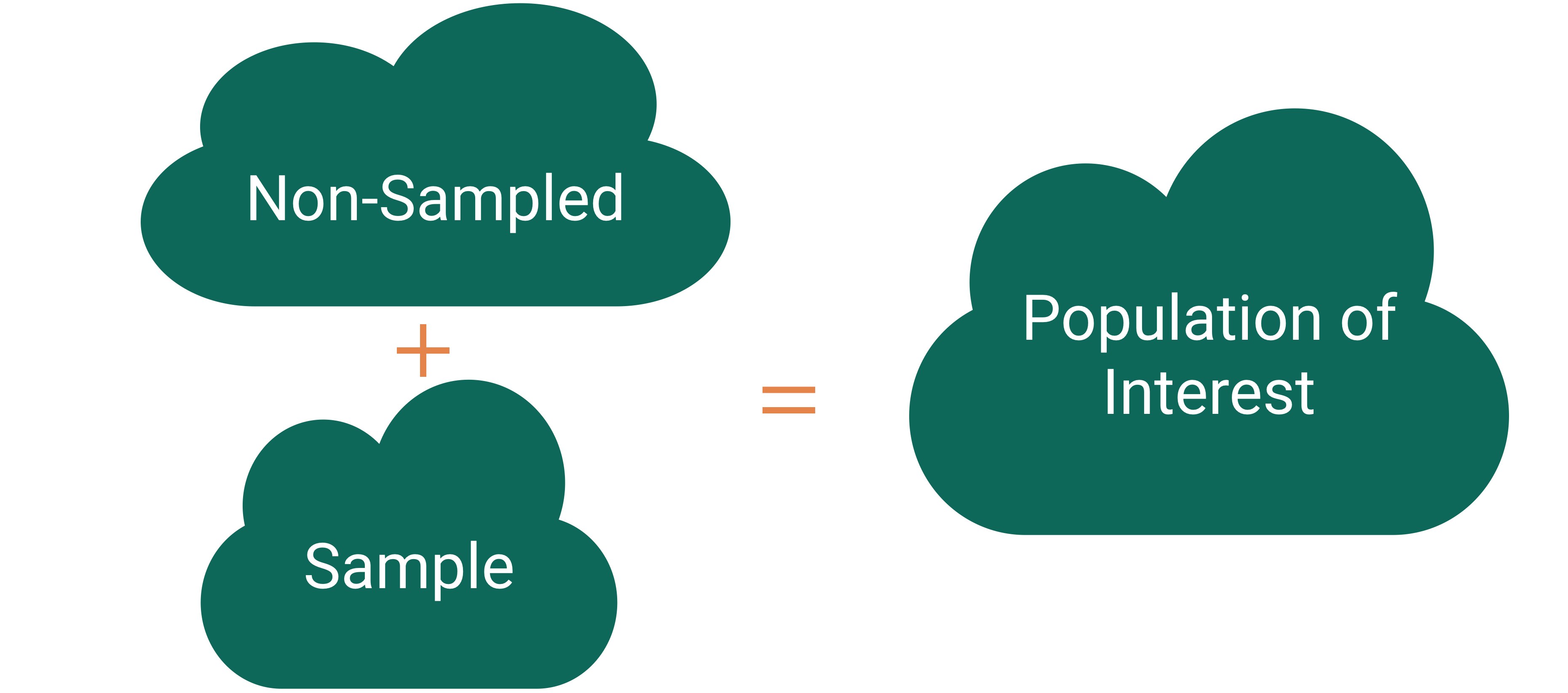
Sampling bias: When the sampled units are systematically different from the non-sampled units on the variables of interest.
US Forest Inventory and Analysis Program

Mission: “Make and keep current a comprehensive inventory and analysis of the present and prospective conditions of and requirements for the renewable resources of the forest and rangelands of the US.”
Need a random sample of ground plots to say something about the state of our nation’s forests!
FIA: Simple Random Sampling
- Break the landscape up into equally sized plots (~1 acre).
- Number each plot from 1 to 6,755,200.
- Use a random mechanism to sample a plot for about every 6,000 acres.
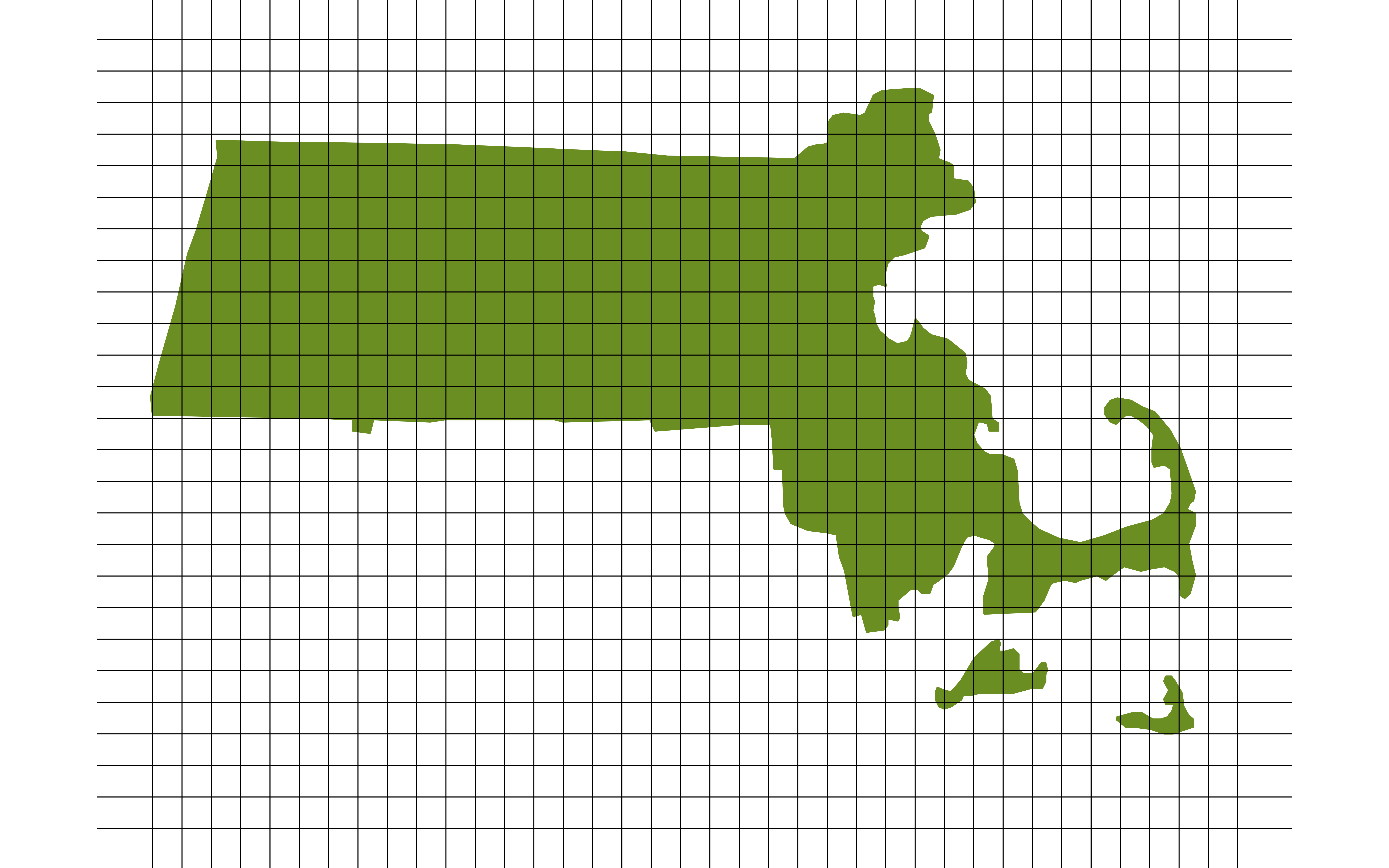
Thoughts on this sampling design?
FIA: Cluster Random Sampling
- Break the landscape up into equally sized plots (~1 acre).
- Put each plot in a cluster.
- For our example: cluster = county.
- Number each cluster.
- Use a random mechanism to sample 2 clusters.
- Sample all plots in those 2 clusters.
Thoughts on this sampling design?
FIA: Cluster Random Sampling
- Break the landscape up into equally sized plots (~1 acre).
- Put each plot in a cluster.
- For our example: cluster = county.
- Number each cluster.
- Use a random mechanism to sample 2 clusters.
- Take a simple random sample within the sampled clusters.
Subsampling within each sampled cluster is much more common than subsampling the whole sampled cluster!
FIA: Cluster Random Sampling
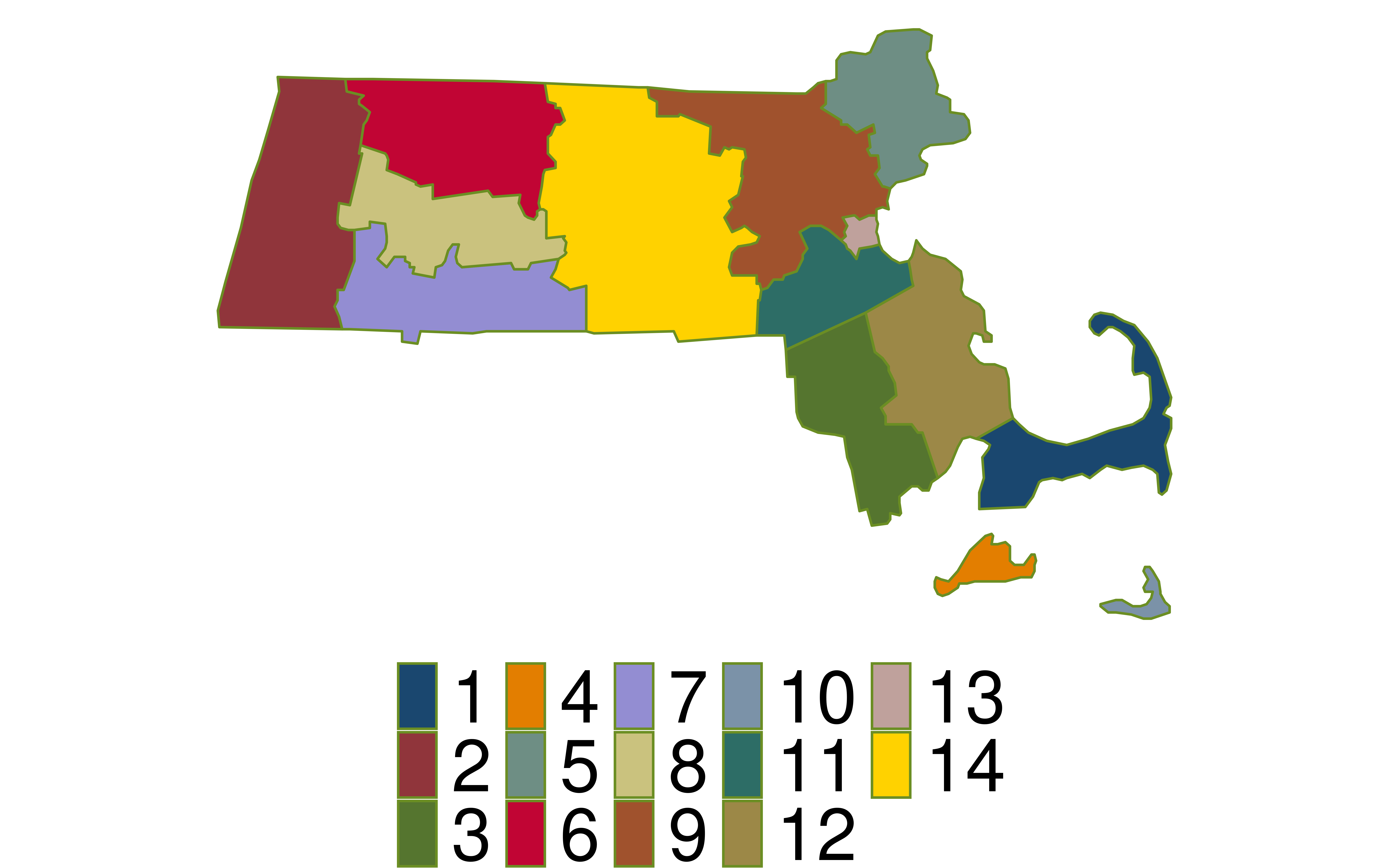
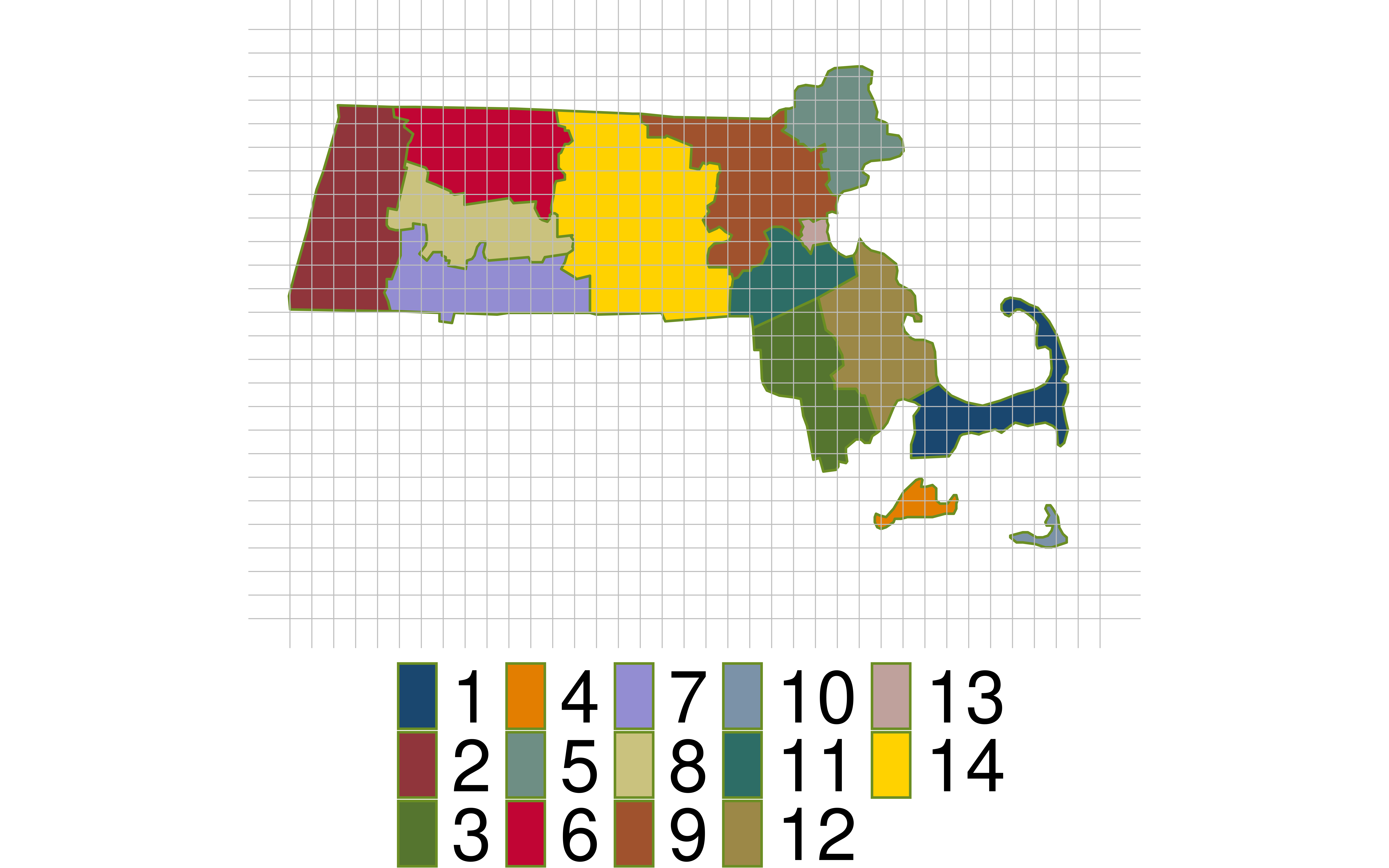
Are our clusters based on counties homogeneous?
Why is homogeneity important for cluster sampling?
FIA: Stratified Random Sampling
- Break the landscape up into equally sized plots (~1 acre).
- Put each plot in a stratum.
- For our example: stratum = county.
- Take a simple random sample within every stratum.
- Don’t have to be equally sized!
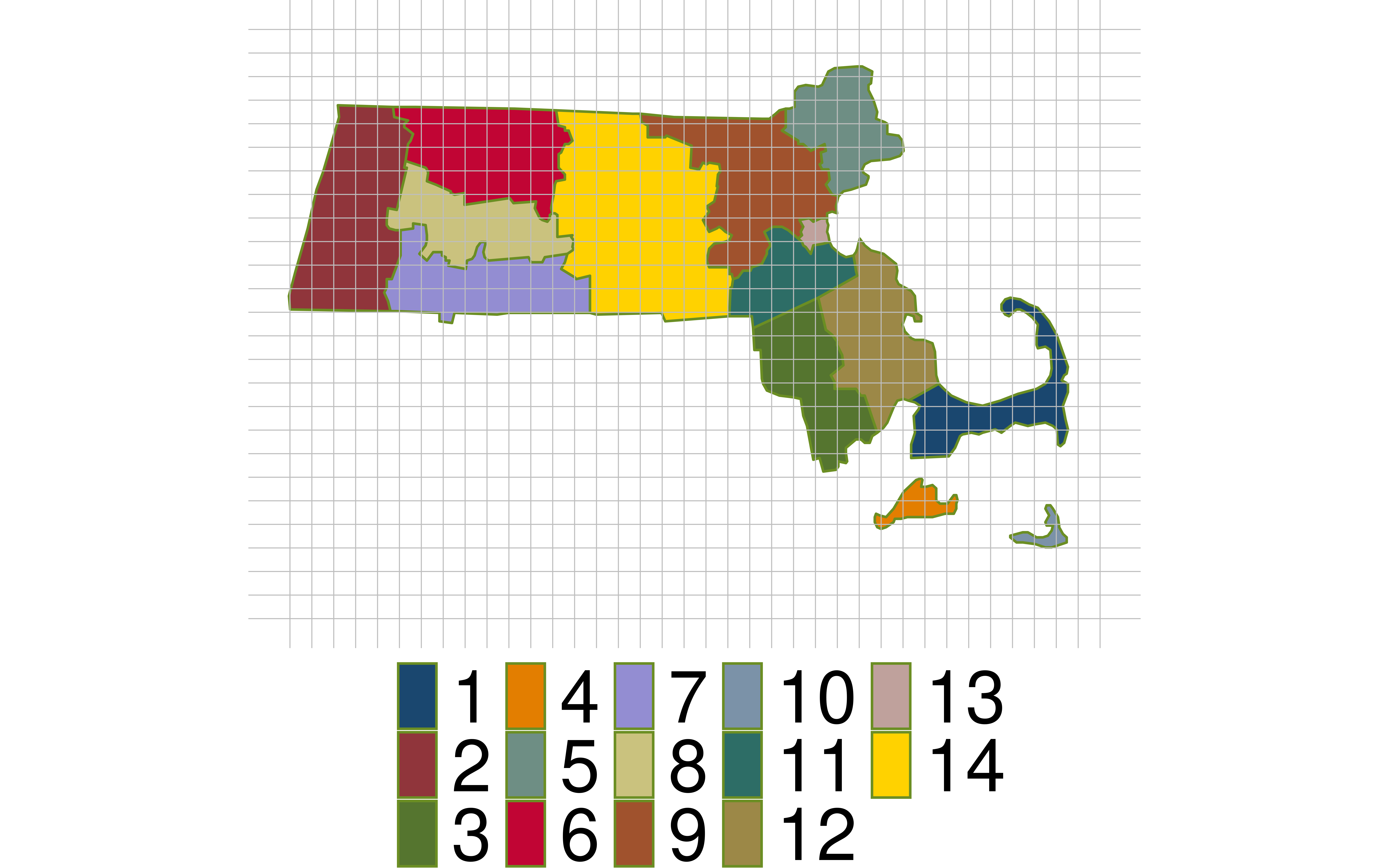
Thoughts on this sampling design?
FIA: Systematic Random Sampling
This is FIA’s actual sampling design (okay, slightly simplified).
- Break the landscape up into equally sized plots (~1 acre).
- Number each plot from 1 to 6,755,200.
- Use a random mechanism to pick starting point. Then sample about once every 6000 acres.
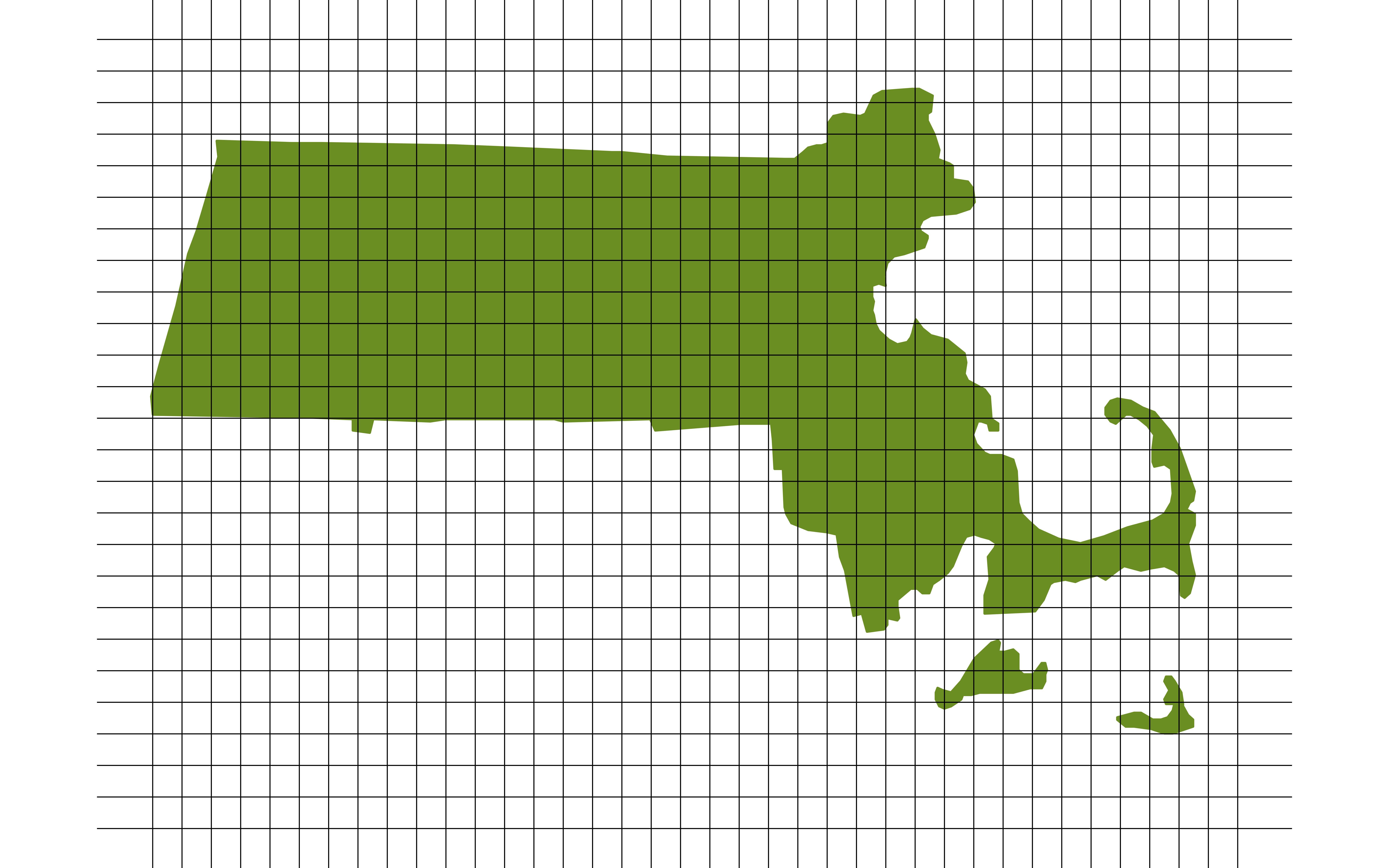
Why is this design better than simple random sampling?
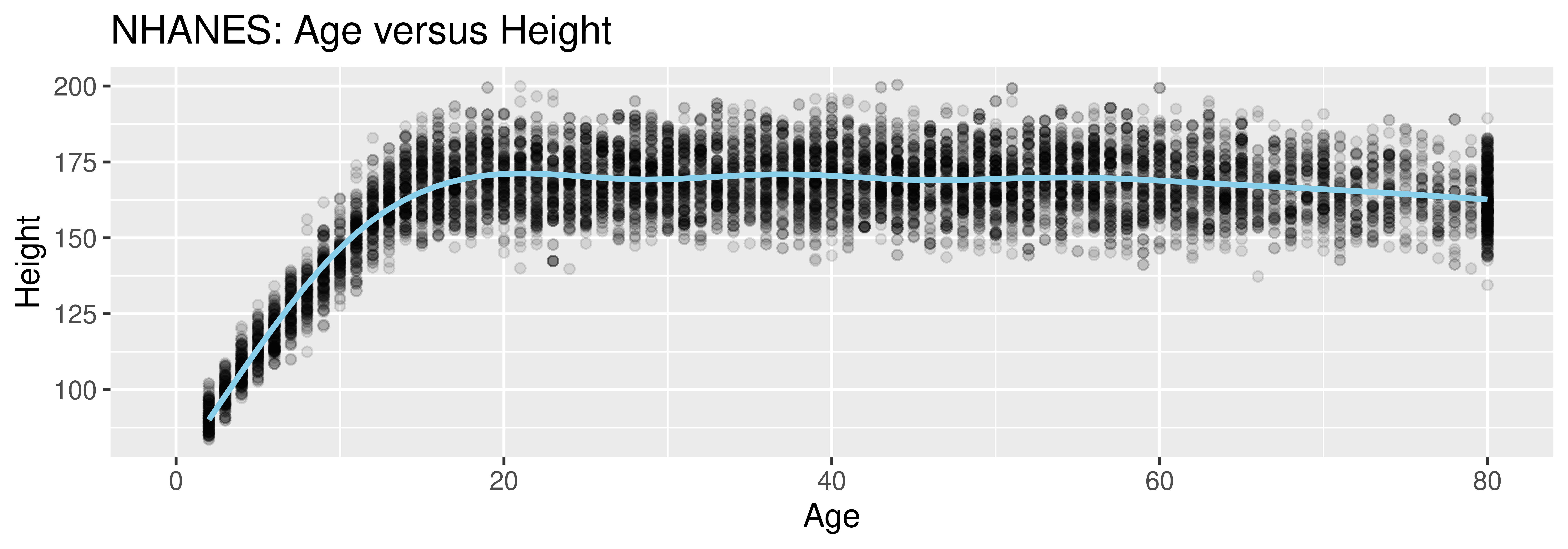
National Health and Nutrition Examination Survey
![]()
Mission: “Assess the health and nutritional status of adults and children in the United States.”
How are these data collected?
Careful Using Non-Simple Random Sample Data
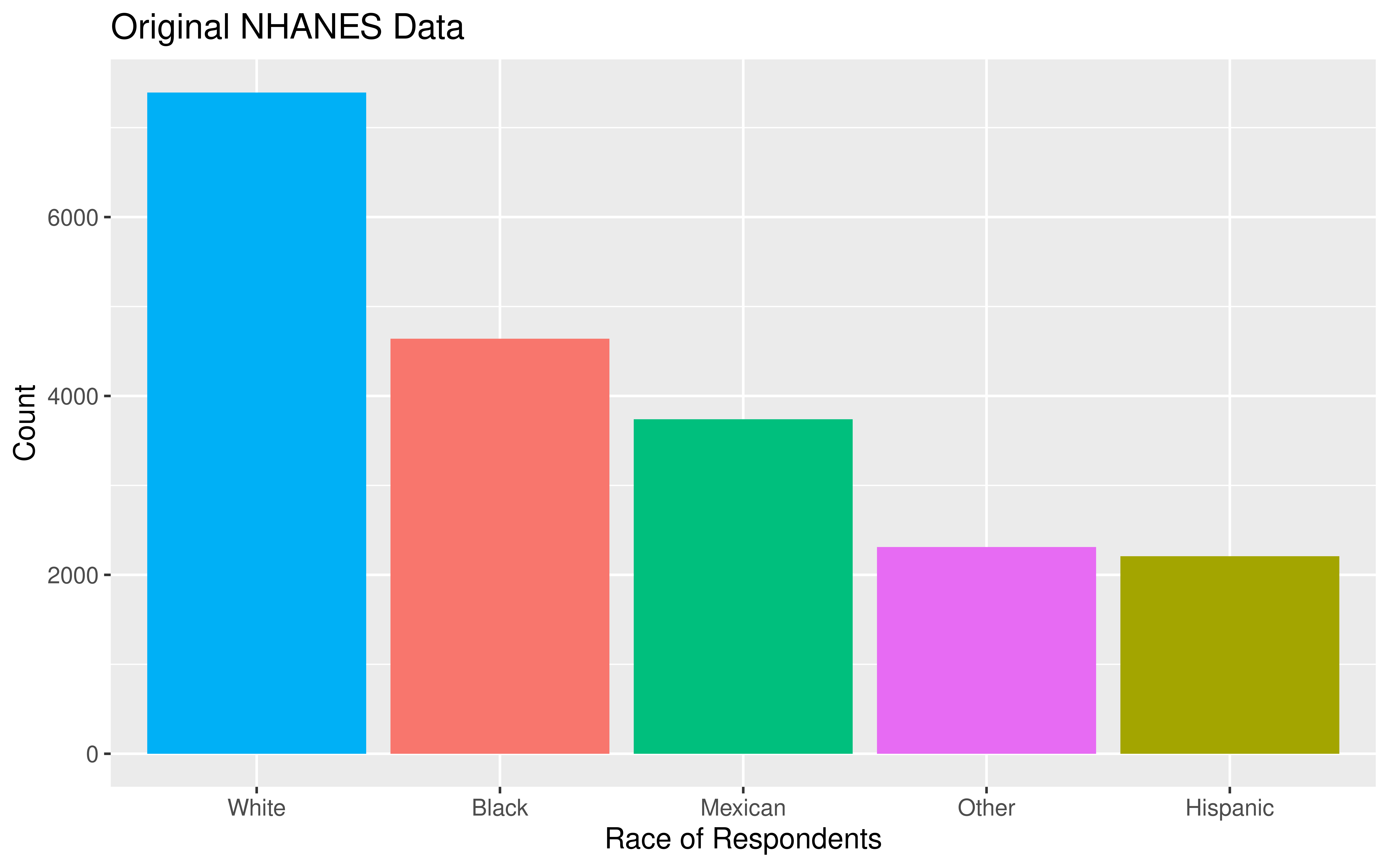
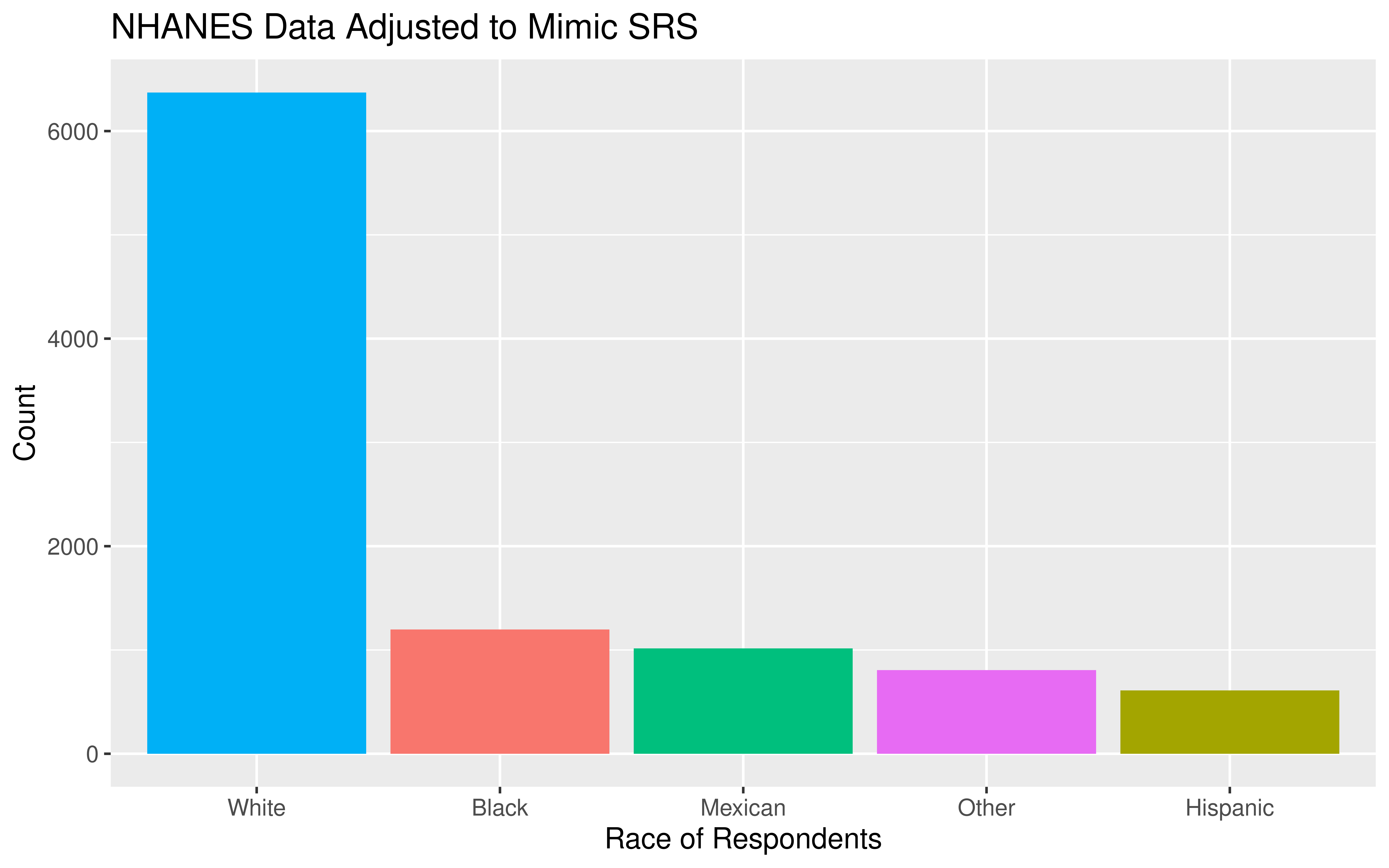
- If you are dealing with data collected using a complex sampling design, I’d recommend taking an additional stats course, like Stat 160: Intro to Survey Sampling & Estimation!
Responsibilities to Research Subjects
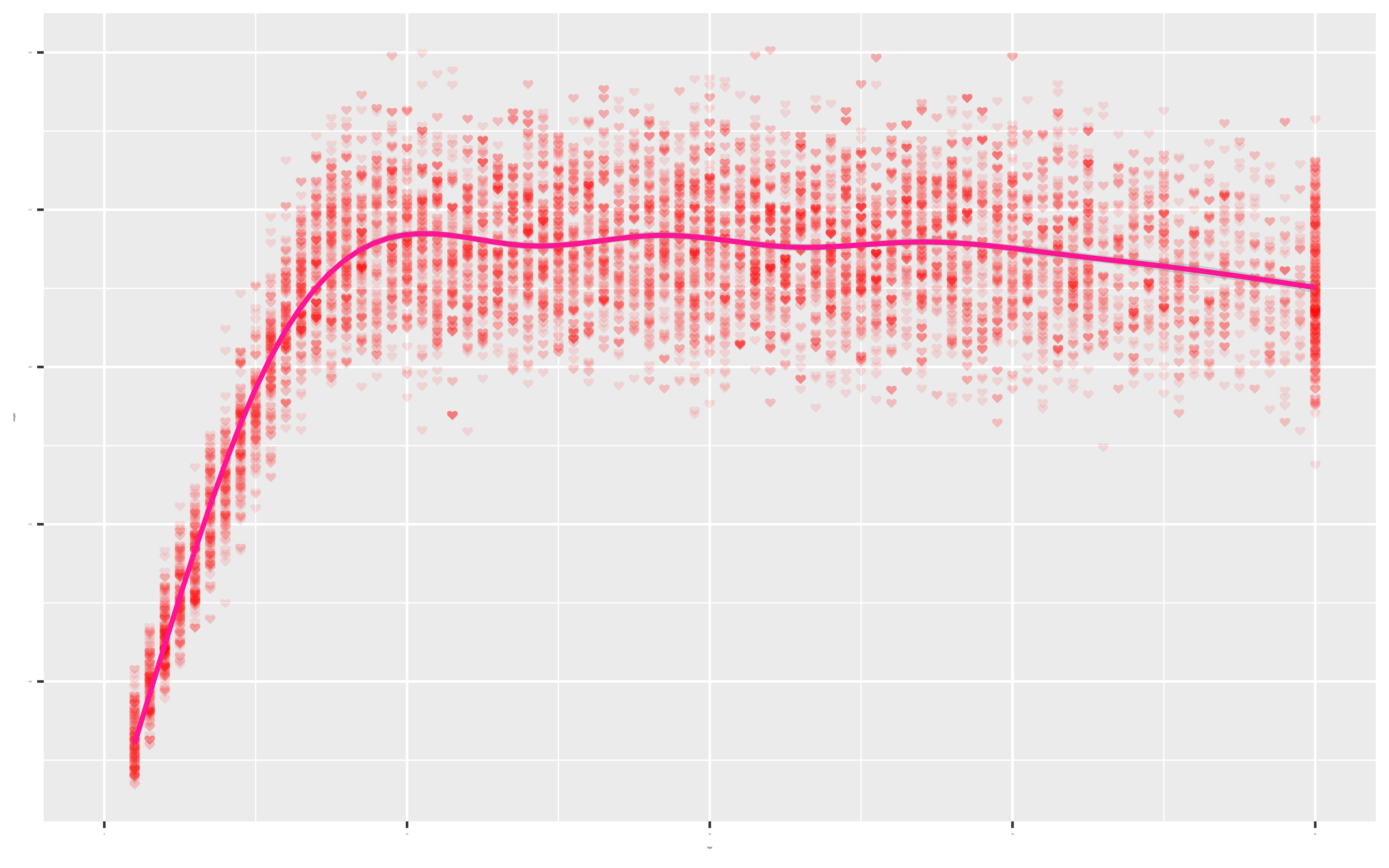
Why do you think the Age variable maxes out at 80?
“Protects the privacy and confidentiality of research subjects and data concerning them, whether obtained from the subjects directly, other persons, or existing records.”