
Multiple Linear Regression
Kelly McConville
Stat 100
Week 7 | Fall 2023
Exploratory Data Analysis
ggplot(candy, aes(x = factor(chocolate),
y = winpercent,
fill = factor(chocolate))) +
geom_boxplot() +
stat_summary(fun = mean,
geom = "point",
color = "yellow",
size = 4) +
guides(fill = "none") +
scale_fill_manual(values =
c("0" = "deeppink",
"1" = "chocolate4")) +
scale_x_discrete(labels = c("No", "Yes"),
name =
"Does the candy contain chocolate?")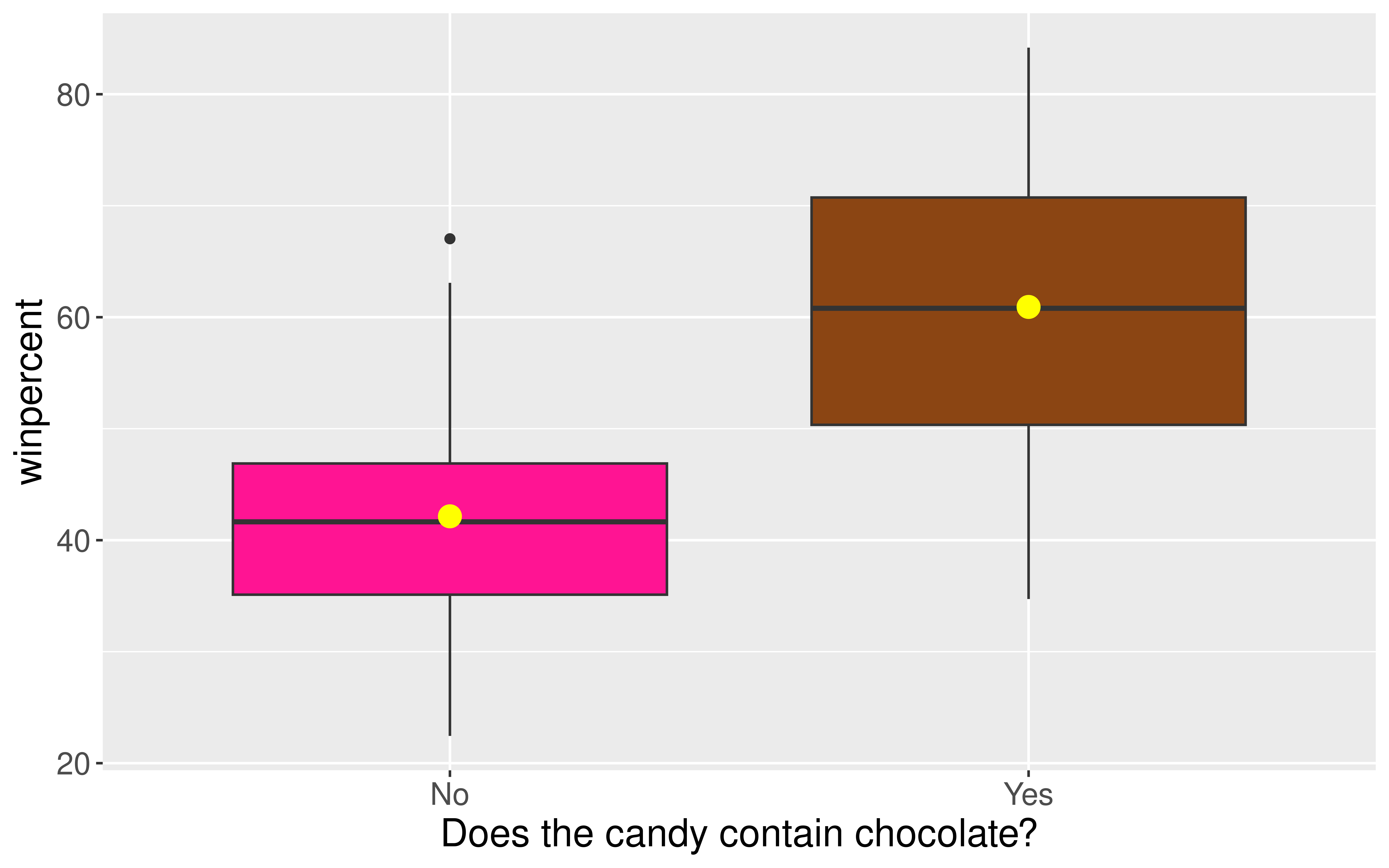
Turns Out Reese’s Miniatures Are Under-Priced…
Visualizing the Data
Why don’t I have to include data = and mapping = in my ggplot() layer?
Appropriateness of Model Form
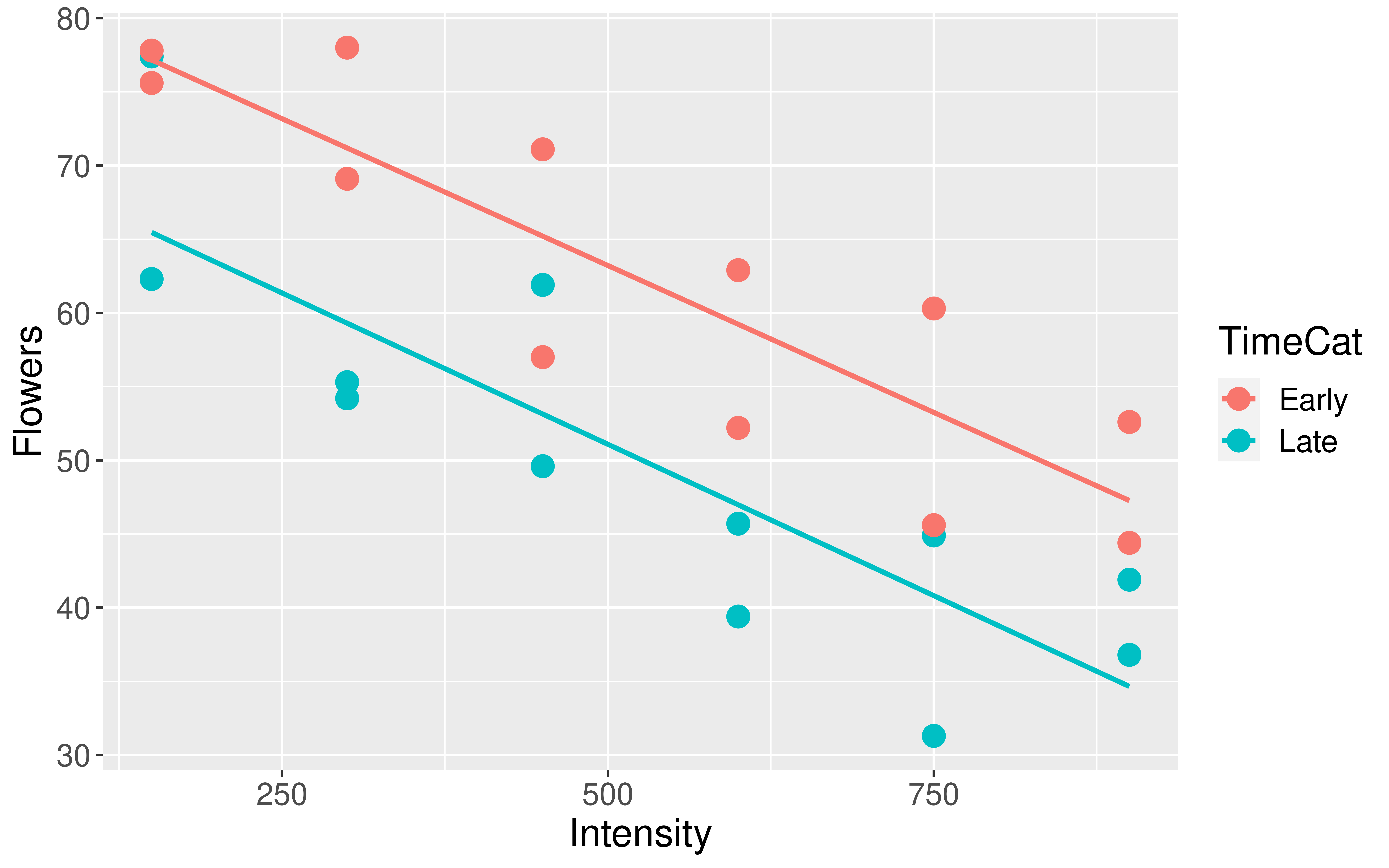
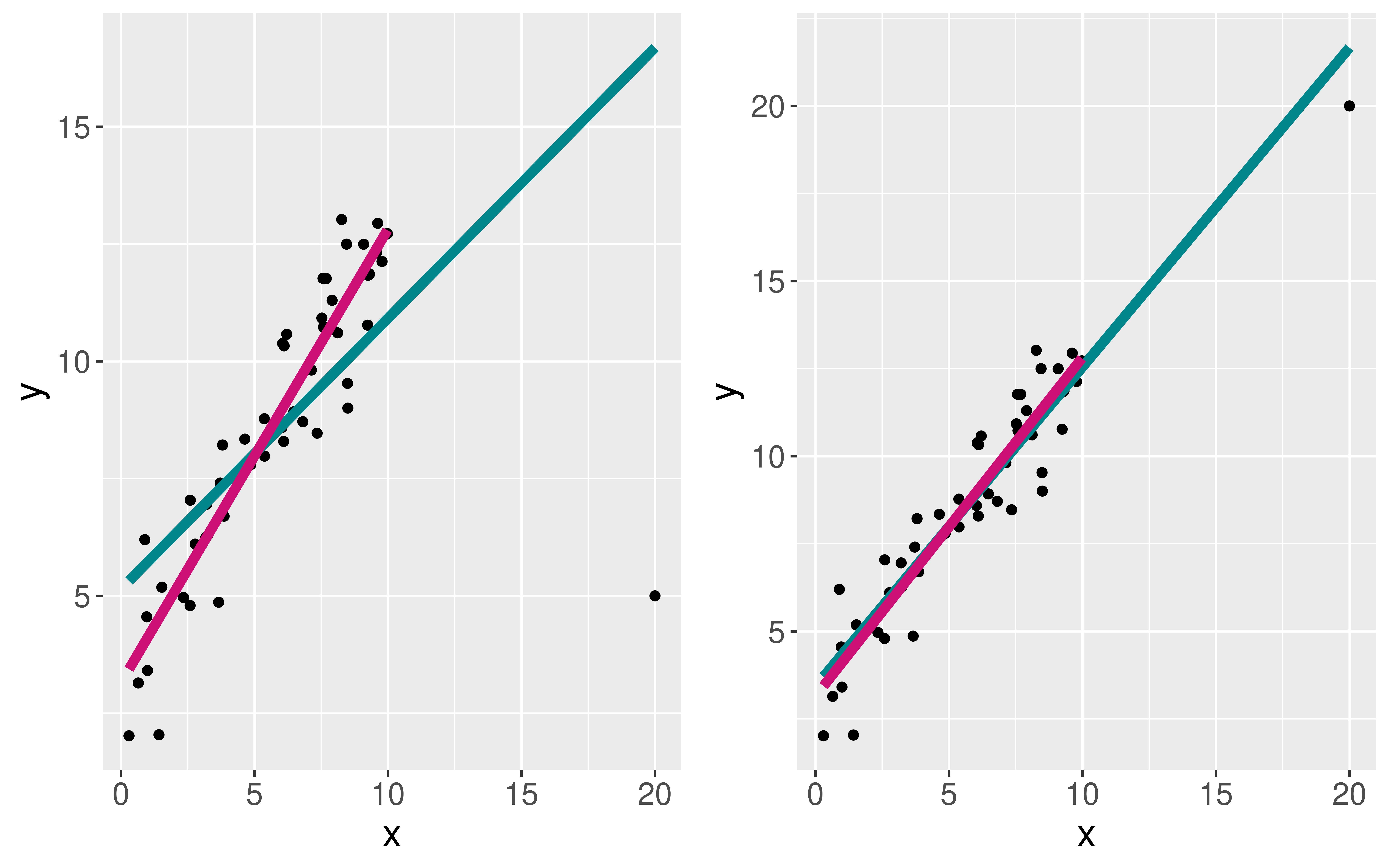
Is the assumption of equal slopes reasonable here?
Visualizing the Data
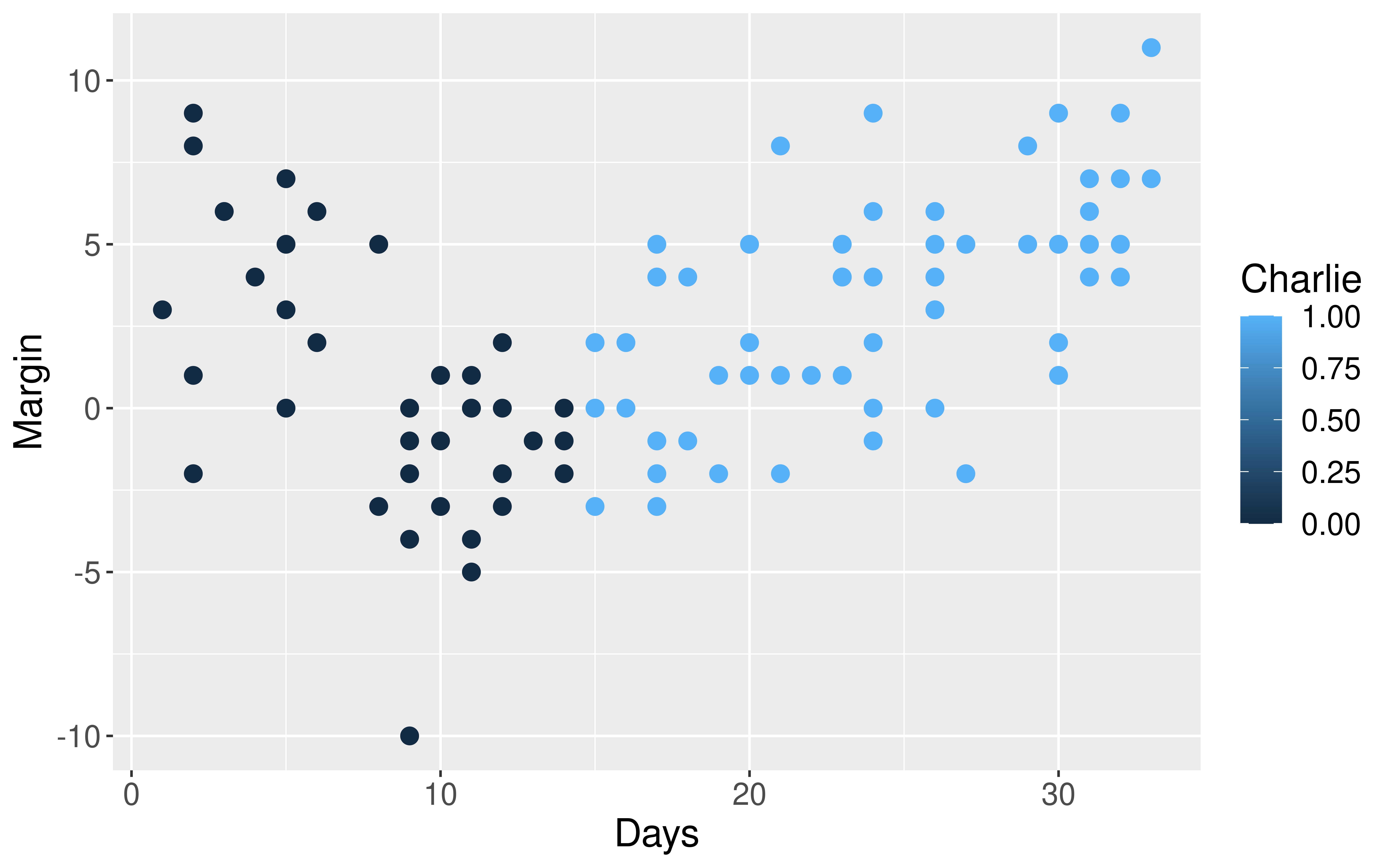
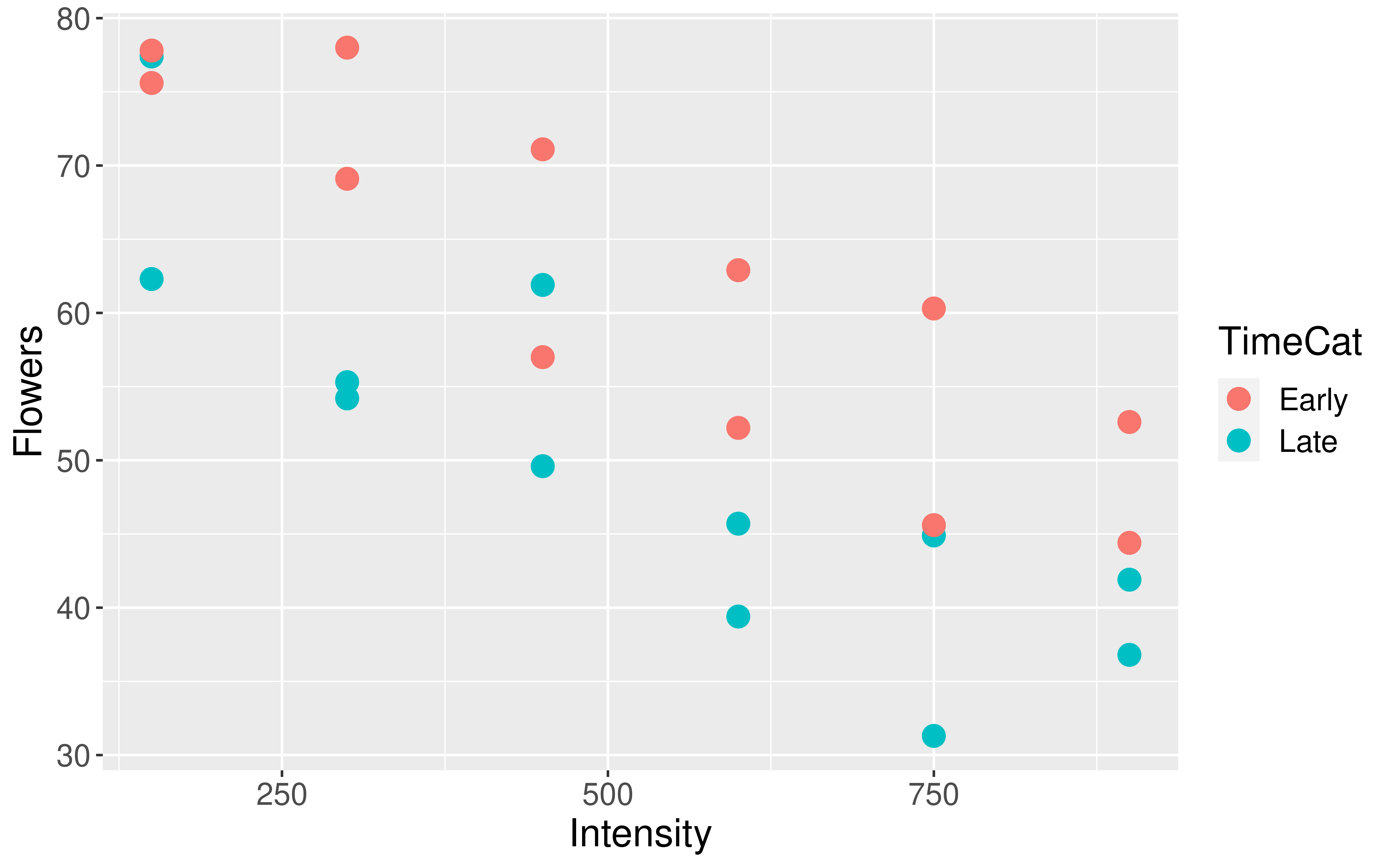
What is wrong with how one of the variables is mapped in the graph?
Visualizing the Data
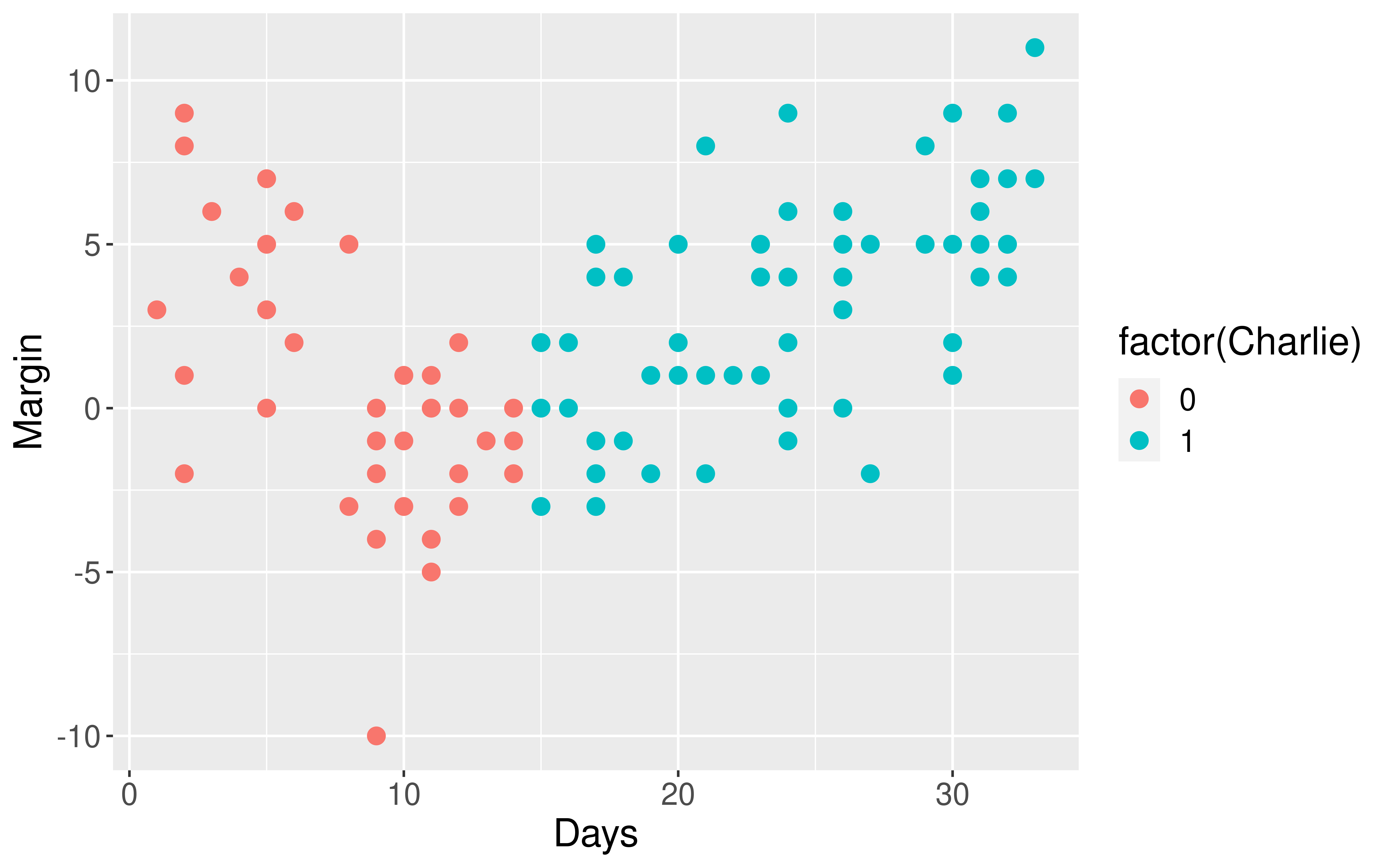
Is the assumption of equal slopes reasonable here?
Adding the Regression Model to the Plot
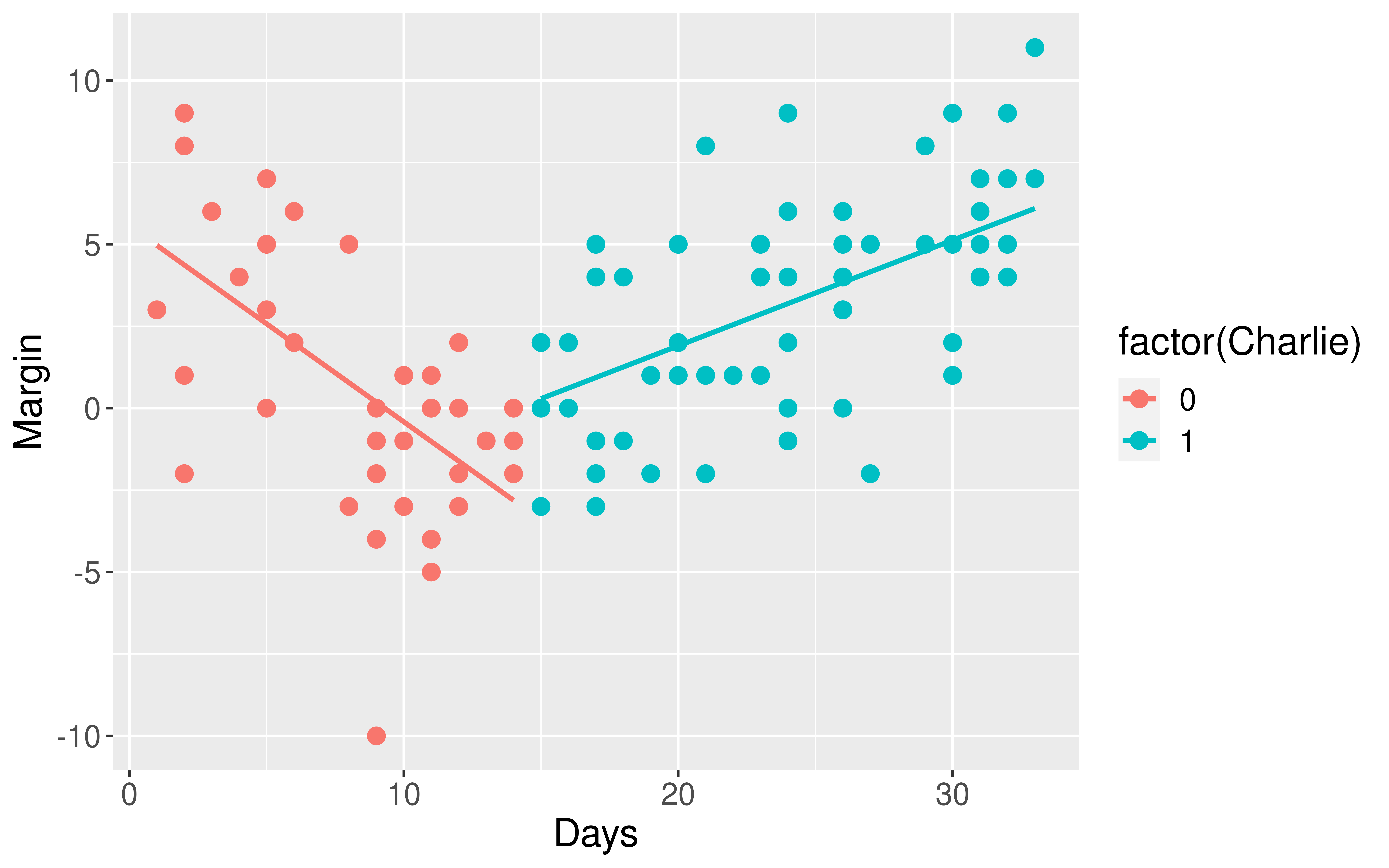
Is our modeling goal here predictive or descriptive?