“The ethical statistical practitioner seeks to understand and mitigate known or suspected limitations, defects, or biases in the data or methods and communicates potential impacts on the interpretation, conclusions, recommendations, decisions, or other results of statistical practices.”
“For models and algorithms designed to inform or implement decisions repeatedly, develops and/or implements plans to validate assumptions and assess performance over time, as needed. Considers criteria and mitigation plans for model or algorithm failure and retirement.”
Algorithmic Bias
Algorithmic bias: when the model systematically creates unfair outcomes, such as privileging one group over another.
Argue for the need for transparency in models that make such important decisions.
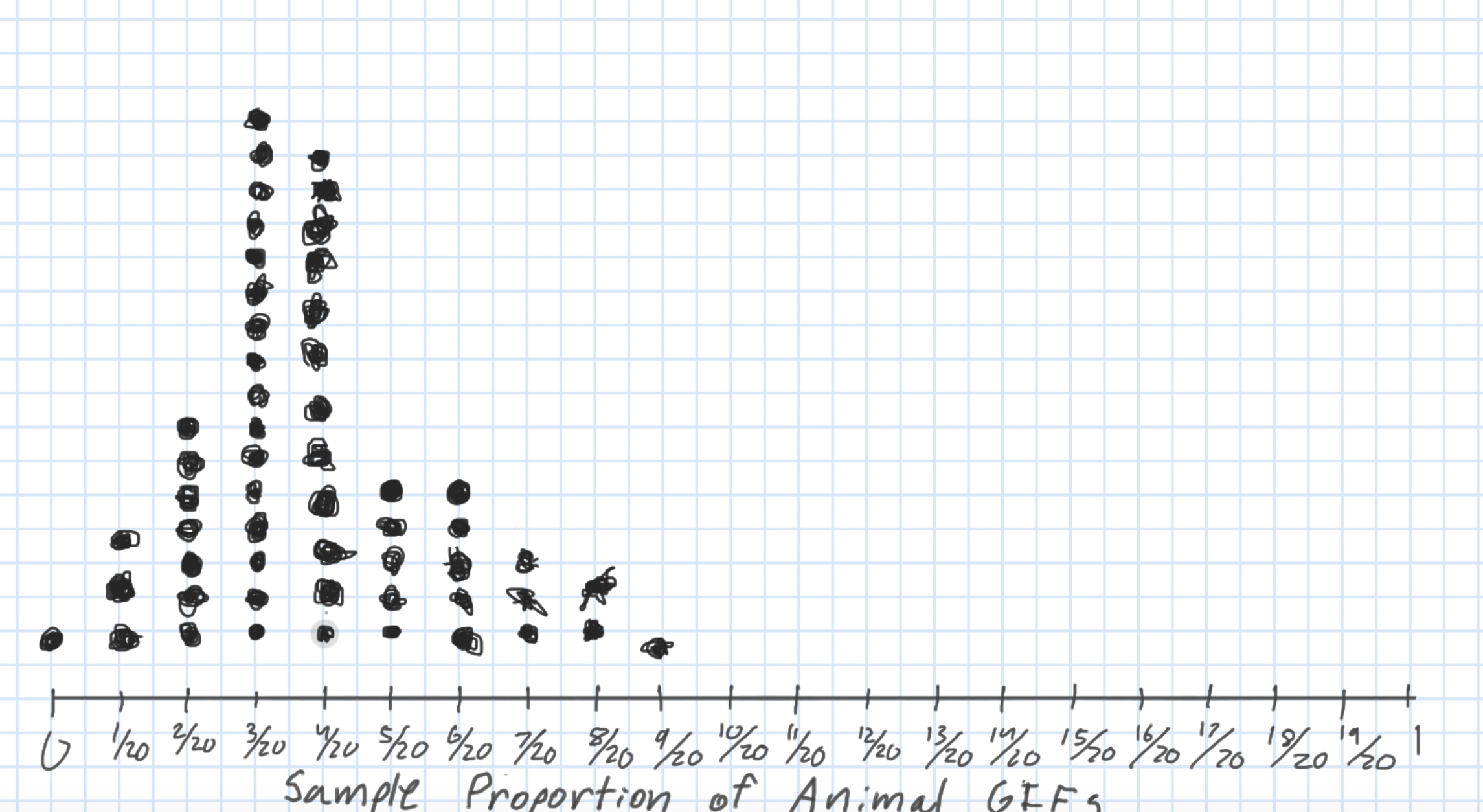
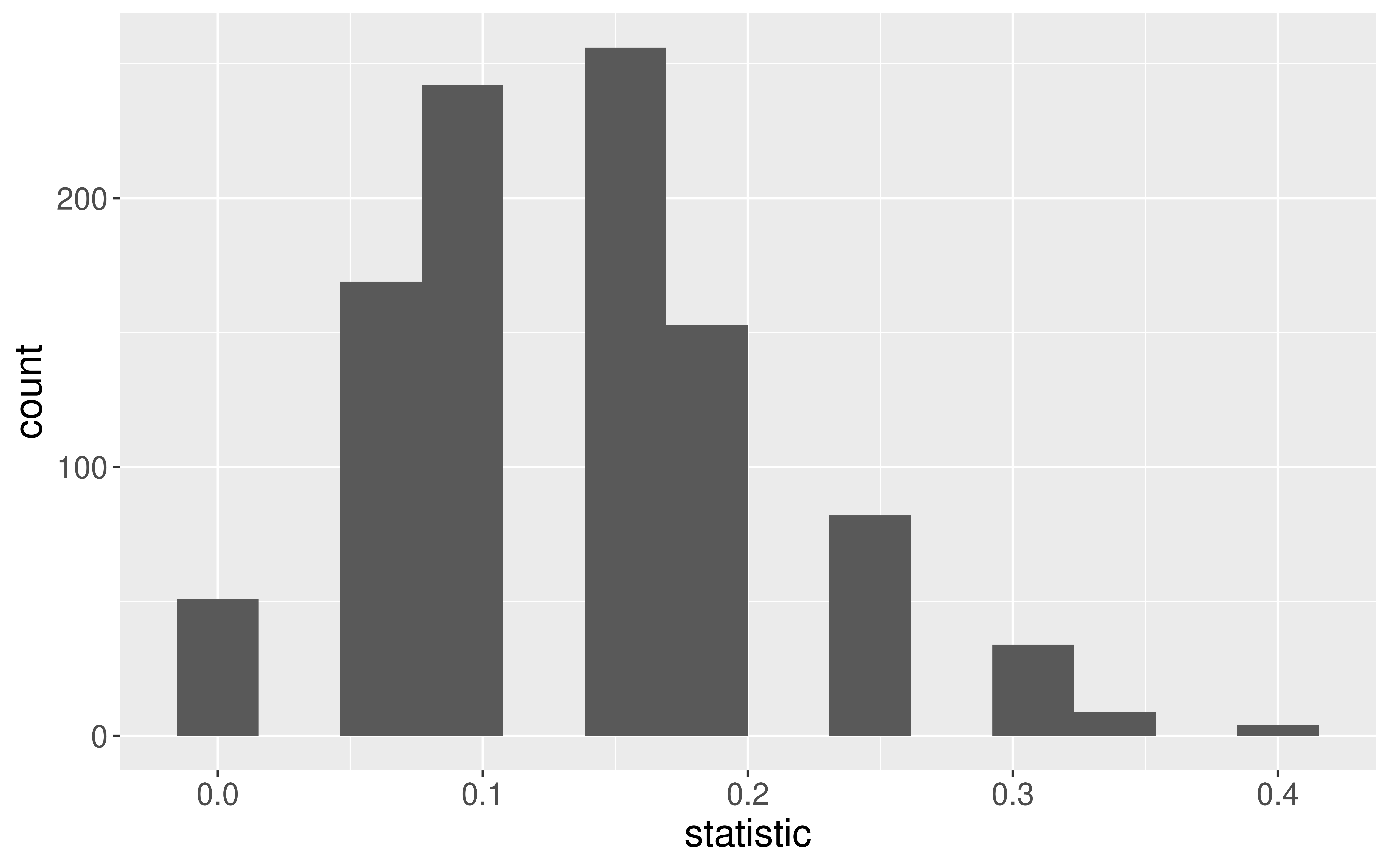
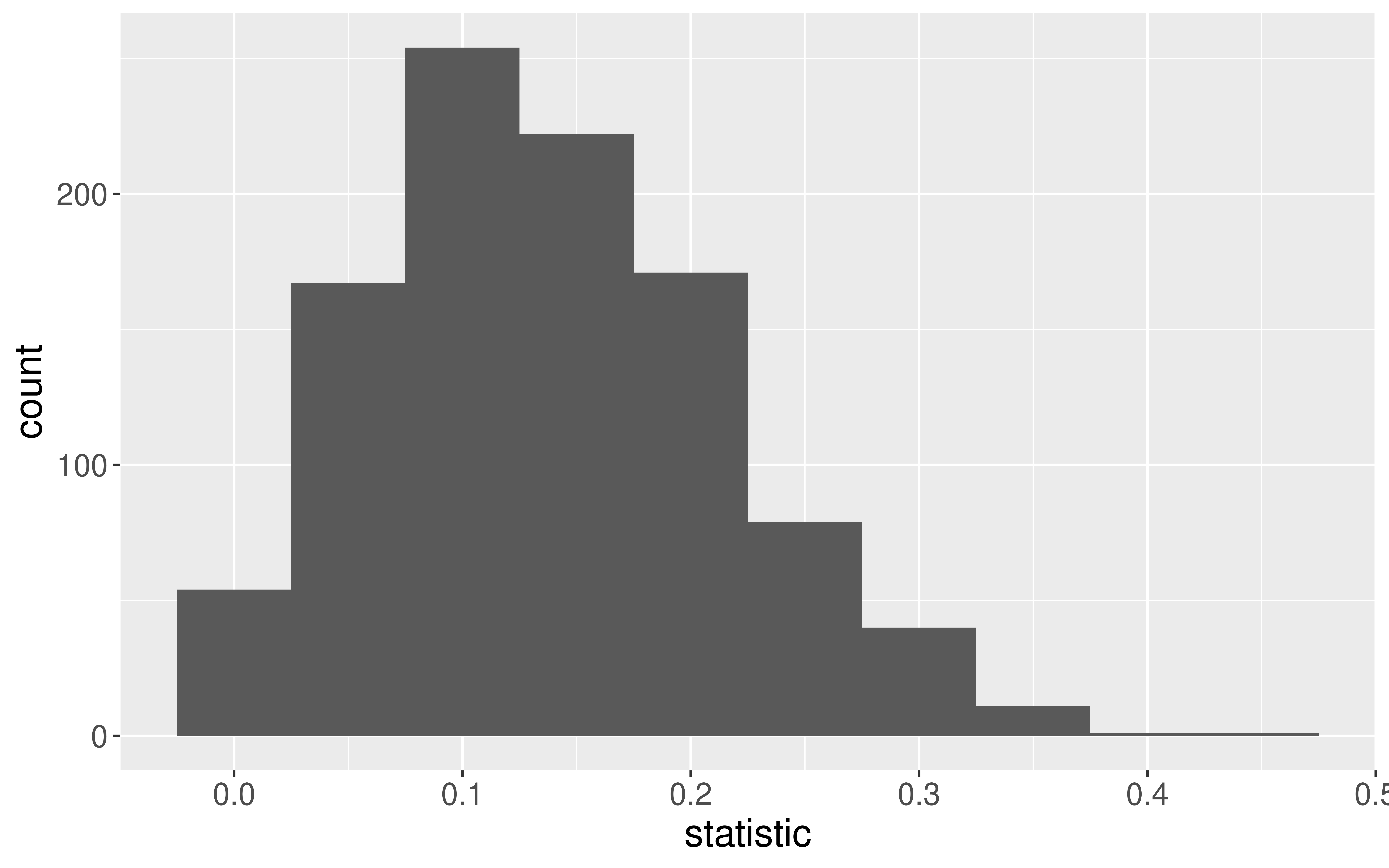
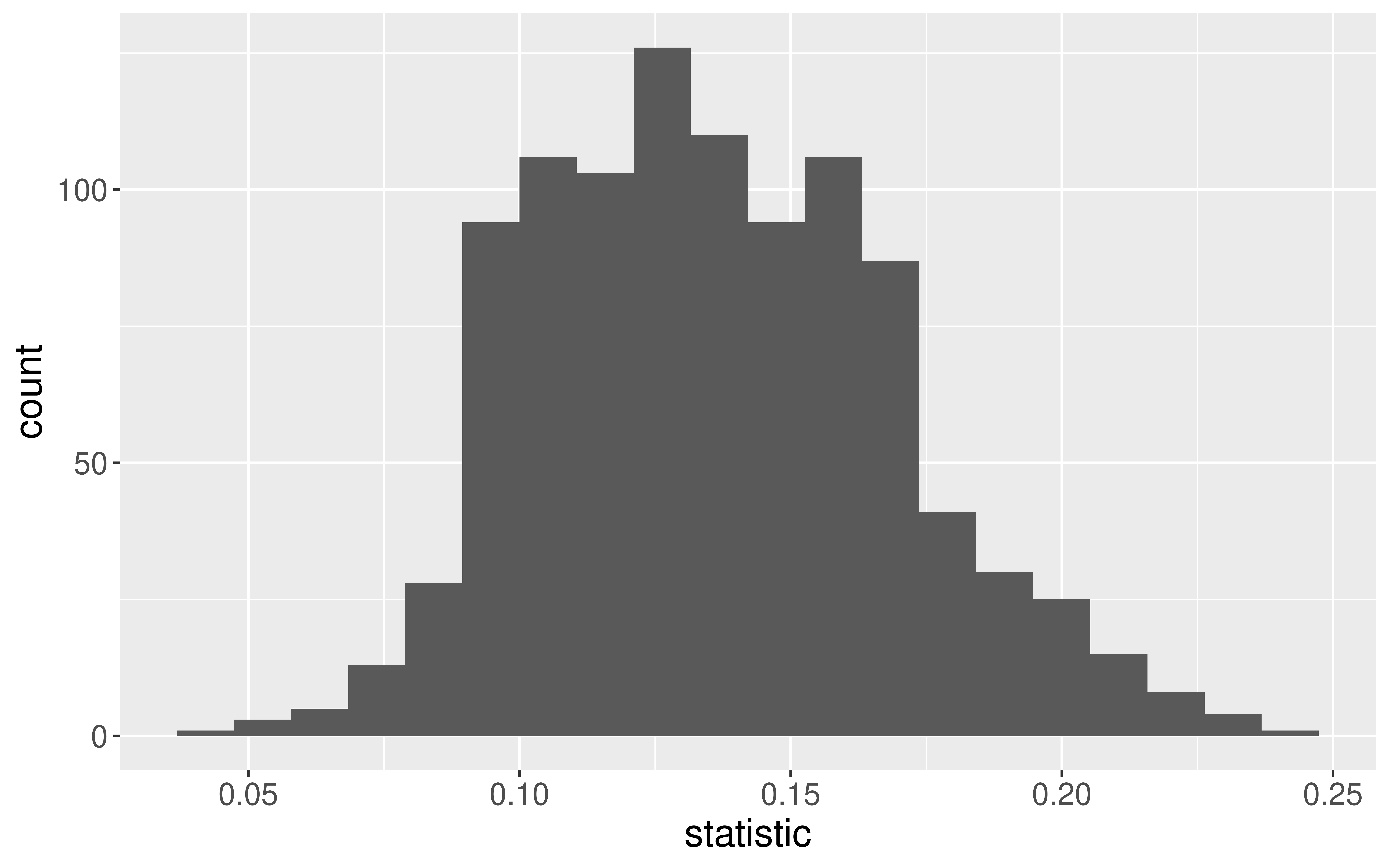
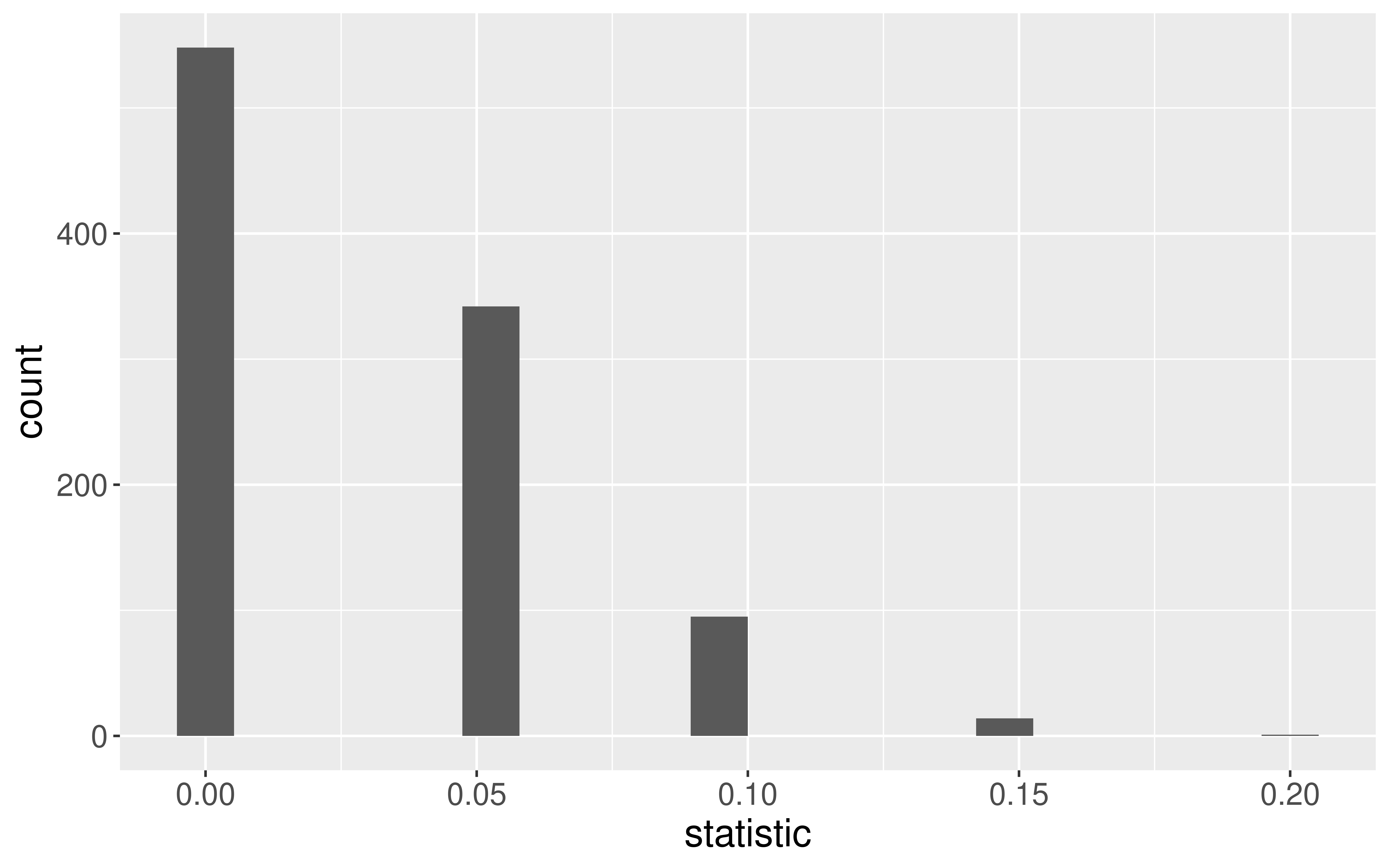
Sampling Distribution of a Statistic
Steps to Construct an (Approximate) Sampling Distribution:
Decide on a sample size, \(n\).
Randomly select a sample of size \(n\) from the population.
Compute the sample statistic.
Put the sample back in.
Repeat Steps 2 - 4 many (1000+) times.
What happens to the center/spread/shape as we increase the sample size?
What happens to the center/spread/shape if the true parameter changes?
Let’s Construct Some Sampling Distributions using R!
Important Notes
To construct a sampling distribution for a statistic, we need access to the entire population so that we can take repeated samples from the population.
Population = Harvard trees
But if we have access to the entire population, then we know the value of the population parameter.
Can compute the exact mean diameter of trees in our population.
The sampling distribution is needed in the exact scenario where we can’t compute it: the scenario where we only have a single sample.
We will learn how to estimate the sampling distribution soon.
Today, we have the entire population and are constructing sampling distributions anyway to study their properties!
It is time to move beyond just point estimates to interval estimates that quantify our uncertainty.
summarize(ce, meanFINCBTAX =mean(FINCBTAX))
# A tibble: 1 × 1
meanFINCBTAX
<dbl>
1 62480.
Confidence Interval: Interval of plausible values for a parameter
Form: \(\mbox{statistic} \pm \mbox{Margin of Error}\)
Question: How do we find the Margin of Error (ME)?
Answer: If the sampling distribution of the statistic is approximately bell-shaped and symmetric, then a statistic will be within 2 SEs of the parameter for 95% of the samples.
Form: \(\mbox{statistic} \pm 2\mbox{SE}\)
Called a 95% confidence interval (CI). (Will discuss the meaning of confidence soon)
Confidence Intervals
95% CI Form:
\[
\mbox{statistic} \pm 2\mbox{SE}
\]
Let’s use the ce data to produce a CI for the average household income before taxes.
summarize(ce, meanFINCBTAX =mean(FINCBTAX))
# A tibble: 1 × 1
meanFINCBTAX
<dbl>
1 62480.
What else do we need to construct the CI?
Problem: To compute the SE, we need many samples from the population. We have 1 sample.
Solution: Approximate the sampling distribution using ONLY OUR ONE SAMPLE!
Reminders:
Oct 30th: Hex or Treat Day in Stat 100
Wear a Halloween costume and get either a hex sticker or candy!!