P-Value Pitfalls
Kelly McConville
Stat 100
Week 11 | Fall 2023
Let’s Talk About P-values
A consequence: P-hacking: Cherry-picking promising findings that are beyond this arbitrary threshold.

Let’s Talk About P-values
Despite its issues, p-values are still quite popular and can still be a useful tool when used properly.
In 2014, George Cobb a professor from Mount Holyoke College poised the following questions (and answers):
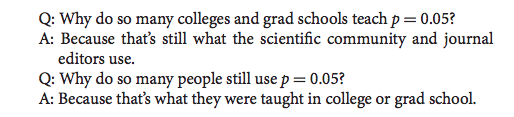
- I want us to stop this cycle.
Reporting Results in Journal Articles

Statistical Inference Zoom Out – Estimation
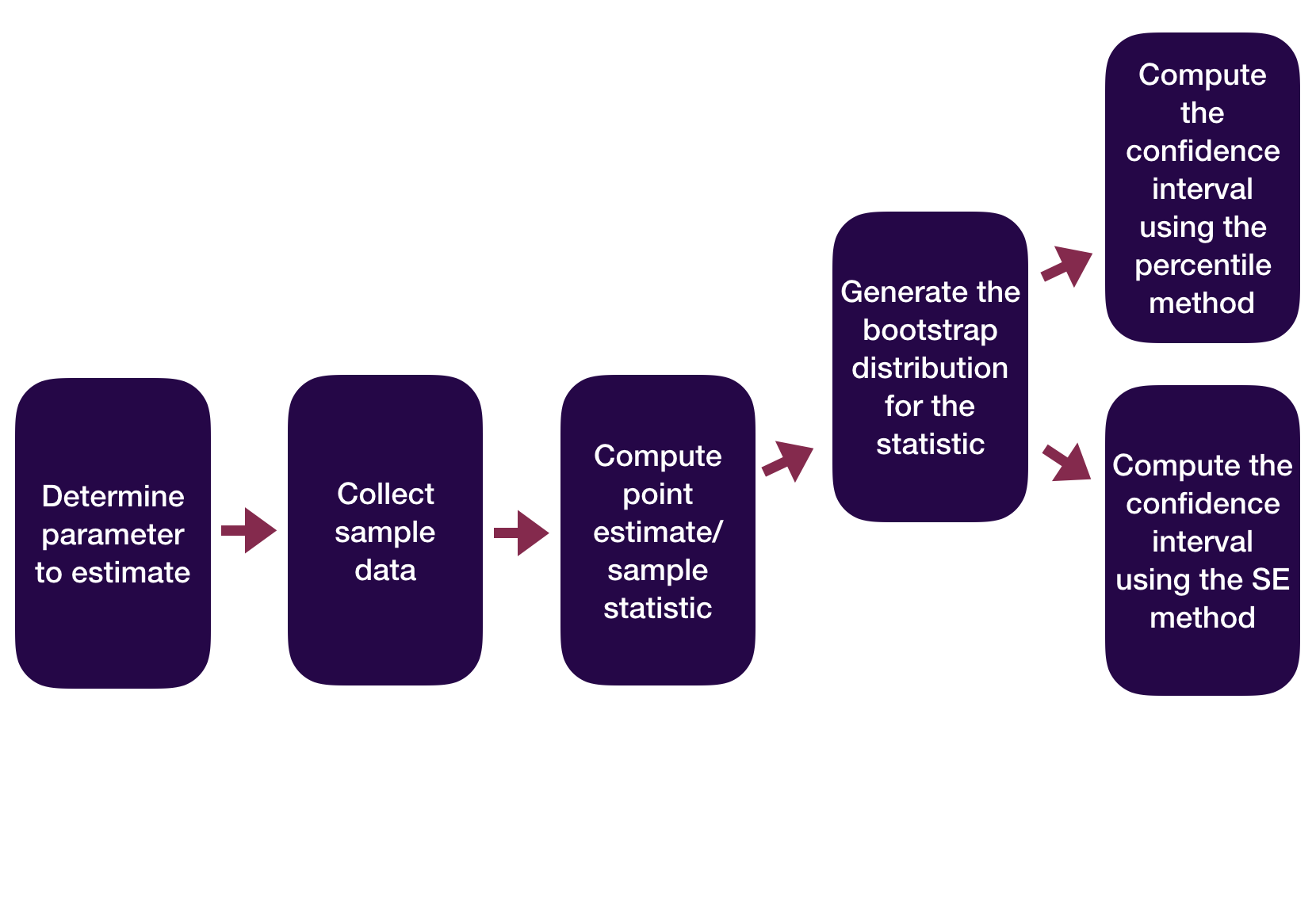
Question: How did folks do inference before computers?
Statistical Inference Zoom Out – Testing
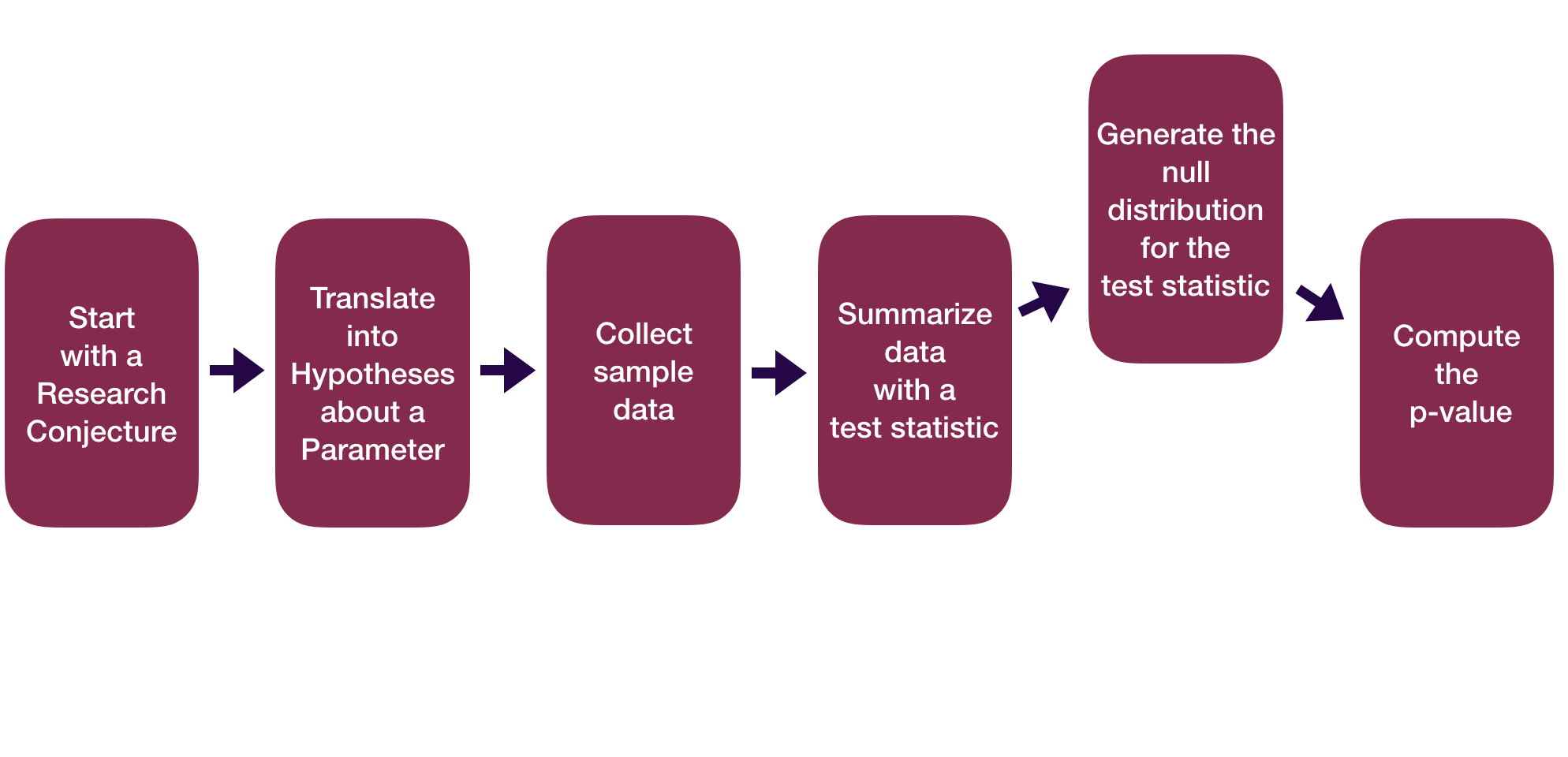
Question: How did folks do inference before computers?
Statistical Inference Zoom Out – Estimation

Question: How did folks do inference before computers?
Statistical Inference Zoom Out – Testing
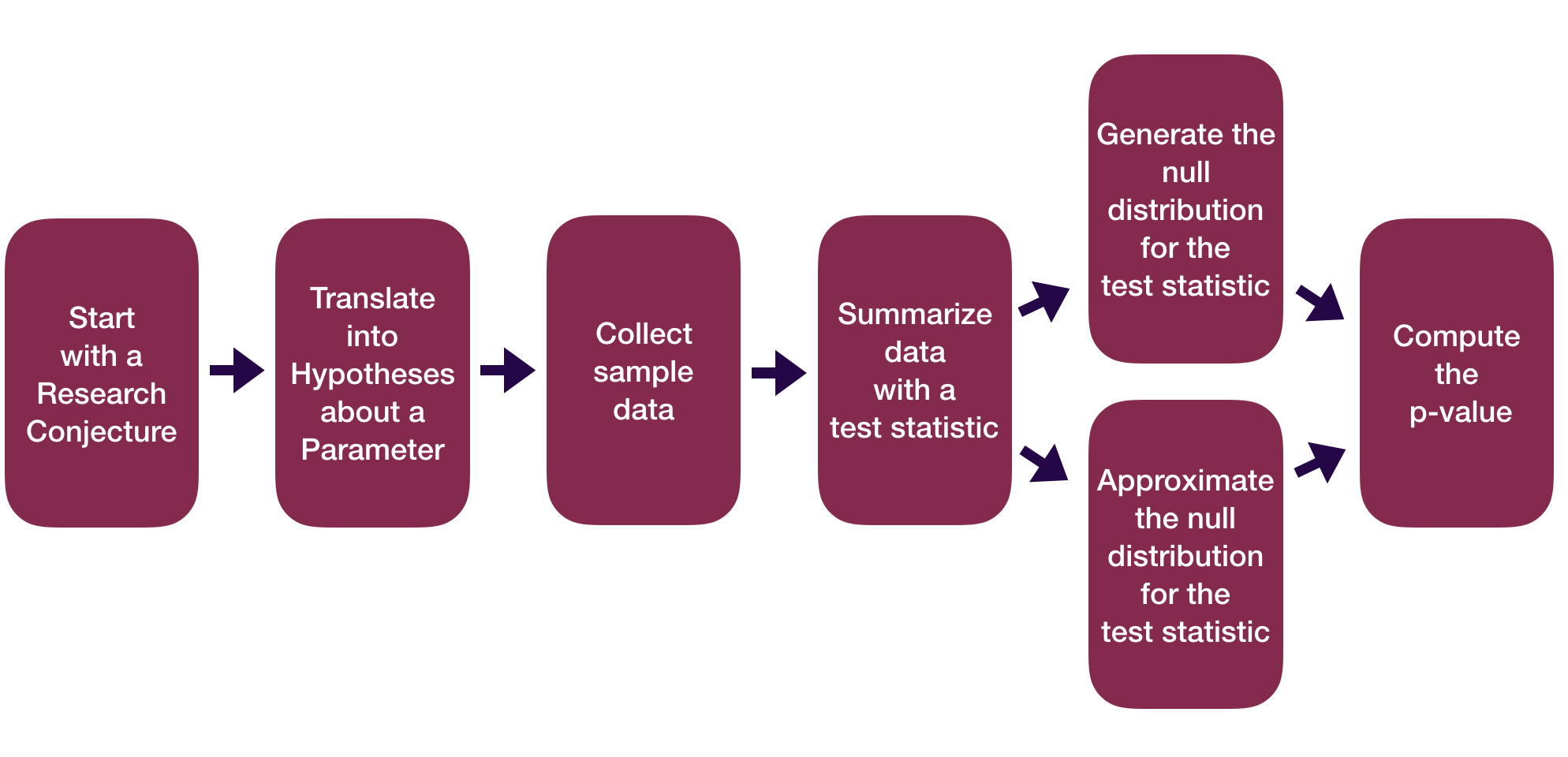
Question: How did folks do inference before computers?
Probability Models
“All models are wrong but some are useful.” – George Box
Question: How can we use theoretical probability models to approximate our (sampling) distributions?
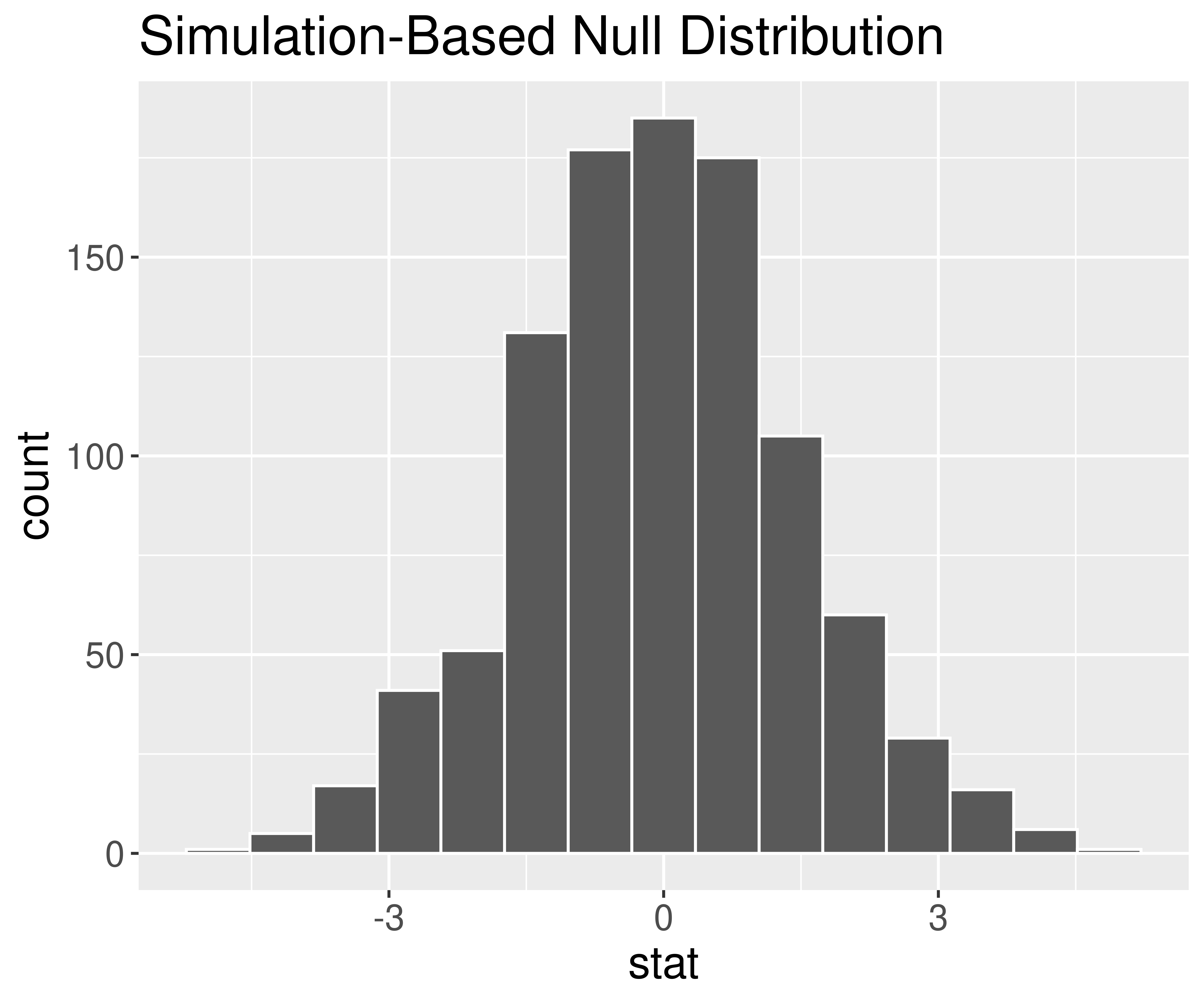
Before we can answer that question, we need to learn some probability concepts that will help us understand these models.
Probability Concepts
Question: Why is the LLN important to us?
Answer: We’ve assuming \(p_m\) and \(p\) are essentially the same thing when computing p-values.
p-value = # of extreme test statistics/# of replications
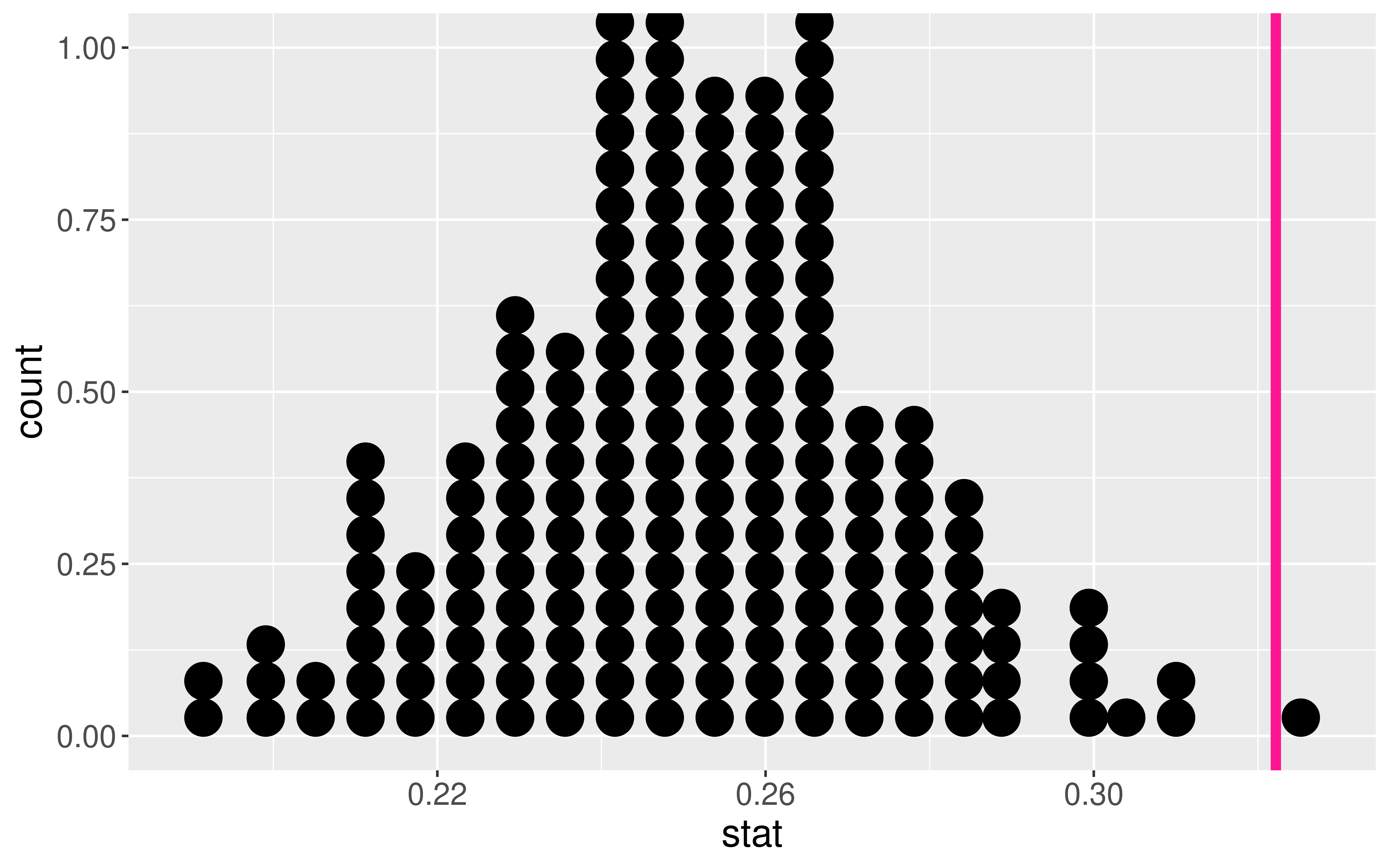
LLN tells us the proportion of extreme test stats is roughly equal to the true probability of observing the test statistic or more extreme under \(H_o\).
Probabilities: \(P(\mbox{event})\)
If two events are disjoints (have no outcomes in common), then
\[ P(\mbox{event 1 or event 2}) = P(\mbox{event 1}) + P(\mbox{event 1}). \]
We use this fact when we find a two-sided p-value.
Probabilities: \(P(\mbox{event})\)
Complement Rule:
\[ P(\mbox{event}) = 1 - P(\mbox{not that event}) = 1 - P(\mbox{event}^c) \]
Sometimes it is “easier” to find the complement event’s probability.